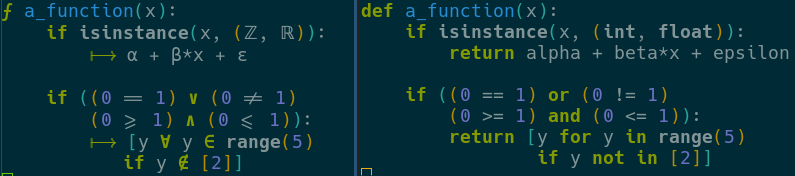

Sequences of characters are represented as a single token using:
- Pretty-mode
- Pretty-mode provides Greeks, subscripts, and more symbols.
- Prettify-symbols-mode
- Prettify Symbols ships with Emacs as of 24.4 and adds support for custom Unicode replacement of symbols.
- Ligatures
- Unicode replacements of common operators (see Fira Code, the font I use, and Pragmata Pro fonts)
Any combination of these tools may be chosen; Fira Code is not required to utilize prettify-symbols or pretty-mode. Similarly, the entire Fira Code font is not required to use Fira’s ligatures.
The replacements are purely visual - searching for “for” will find the for all symbol.
Pretty mode
The package pretty-mode provides default symbol replacements including in, not in, and, or, and greek letters.
Overlap with Fira Code operators can be handled by deactivating the operator, equality, and arrow groups. Sub/superscripts, greek letters, and the sigma summation must be manually activated.
The :logic group overlaps/interferes with prettify-symbols and is disabled.
The :sets group interferes with the int symbol replacement for unknown
reasons. We redefine its symbols in prettify-symbols-mode later.
(require 'pretty-mode)
(global-pretty-mode t)
(pretty-deactivate-groups
'(:equality :ordering :ordering-double :ordering-triple
:arrows :arrows-twoheaded :punctuation
:logic :sets))
(pretty-activate-groups
'(:sub-and-superscripts :greek :arithmetic-nary))
Commented symbols are not replaced, so and and or are fine within
docstrings and comments.
The replacements are entirely visual - searching the buffer for lambda will
find λ.
Check pretty-mode.el for the full list of groups, symbols and supported
modes.
Prettify symbols mode
Prettify mode can be enabled by setting (global-prettify-symbols-mode 1). The
default replacements are major-mode specific. For python, and goes to ∧, or
goes to ∨, and lambda goes to λ.
Additional symbols can be added through prettify-symbols-alist.
(global-prettify-symbols-mode 1)
(add-hook
'python-mode-hook
(lambda ()
(mapc (lambda (pair) (push pair prettify-symbols-alist))
'(;; Syntax
("def" . #x2131)
("not" . #x2757)
("in" . #x2208)
("not in" . #x2209)
("return" . #x27fc)
("yield" . #x27fb)
("for" . #x2200)
;; Base Types
("int" . #x2124)
("float" . #x211d)
("str" . #x1d54a)
("True" . #x1d54b)
("False" . #x1d53d)
;; Mypy
("Dict" . #x1d507)
("List" . #x2112)
("Tuple" . #x2a02)
("Set" . #x2126)
("Iterable" . #x1d50a)
("Any" . #x2754)
("Union" . #x22c3)))))
Some changes are aggressive, mix and match codes to your taste.
The command insert-char, C-x 8 RET prompts for Unicode characters by name
and inserts at point. There is also describe-char, M-m h d c which gives information on the character at point. Use in conjunction with eg. Math Unicode Symbols List to explore your options.
You may encounter some Unicode symbols not rendering despite having a containing font installed.
Use (set-fontset-font "fontset-default" '(#x1d4d0 . #x1d4e2) "Symbola") to
force a font for particular characters. Here I’ve set MATHEMATICAL BOLD SCRIPT
CAPITAL A/S to use Symbola. You can check which fonts support which
characters here.
Ligatures
UPDATE: The original implementation of ligatures for Emacs is no longer hosted. Check out my package that implements fira code
To enable them, you need to add:
(pretty-fonts-set-kwds
'((pretty-fonts-fira-font prog-mode-hook org-mode-hook)))
The ligatures require the FiraCodeSymbol font, not the entire fira code font. Here is a link to the ligatures font to be installed: https://github.com/tonsky/FiraCode/files/412440/FiraCode-Regular-Symbol.zip.
Some of the asterisk ligatures can conflict with org-mode headers and others I
just did not like. I have disabled ligatures for
#Xe101,102,103,104,105,109,12a,12b,14b,14c,16b.
Caveats
For ligatures, the number of visual points composing the replacement is the same as its composing characters. For instance, the ligature for -> occupies two spaces.
But this is not the case for prettify-symbols or pretty-mode. Both alpha and
not in are reduced to one character.
So the line width you see may not be the same as its actual width.
This has two effects:
- A line could then exceed 80 characters with prettify-mode disabled.
- Indentation is performed using the Unicode replacements, not actual spacing.
To circumvent these problems I would recommend:
- Using a linter like pylint which shows infractions for actual line width.
- A pre/post-processing hook that disables prettify, indents the buffer, saves/exports/commits, then re-enables prettify and indents.
Also only ligatures will export to html.
My experience
I have found these changes to improve code readability significantly.
- I can instantly tell the exit points of a function and distinguish if it is a generator.
- Logicals and comparisons are easy to parse. Similarly, distinguishing between in and not in is now instantaneous.
- Lambdas are less cumbersome.
- Mypy types are debatably more natural to read as symbols.
- True, False, and None stand out.
Then there is subjective eye-candy considerations.
Besides the discussed caveats, the main downside is the disassociation between what you see and what you type. In my experience this has not been an issue and the adjustment has been quick.